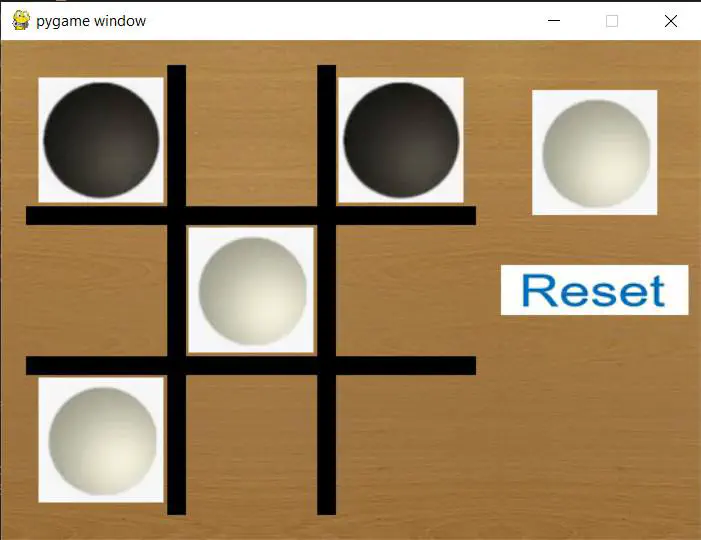
This project is a personal endeavor aimed at learning and applying Tabular Reinforcement Learning. The chosen experimental domain is the game of Tic Tac Toe.
I have implemented three algorithms in Python: SARSA, Q-learning, and double Q-learning. Additionally, I’ve created a game framework that supports human vs. human, human vs. AI, and AI vs. AI gameplay.
Due to the limited number of states in the Tic Tac Toe game, Tabular Reinforcement Learning is sufficient for implementation. I’ve trained both the first player and the second player as two separate agents, and they do not share values between them.
Through experiments, regardless of the algorithm used (SARSA, Q-learning, and double Q-learning), the agents have been trained to the point where they can never lose. The best result for human player is tie, and if human make any mistake the AI will win.
You are very welcomed to click the Code link to github, and deploy on your own computer to play. Also please checkout the Video for your reference.
I’m also conducting research on implementing a chess AI using Alpha Zero’s techniques, which involve Deep Reinforcement Learning and Monte Carlo Tree Search. Chess has significantly more states compared to Tic Tac Toe, and it has been proven that Tabular Reinforcement Learning is not applicable in this case.
Liyang Wang
Senior Supervisor R&D Engineer
My research interests include robotics, reinforcement learning, deep learning, path planning, motion planning, trajectory optimization, and controller design.